Project Training Tests
Testing Methodology
- Set up development environment
- Measure potential base LLMs:
- Identify a set of potential base LLMs to test
- Create a set of at least 10 questions related to security alerts for testing
- Query each test LLM with the list of questions X number of times
- Write output in a set of plaintext files
- Upload these files to ChatGPT to estimate the accuracy of each answer to establish a score for each model
- Perform a manual review of a subset of answers to establish a score for each model
- Compare these two scores and identify the most accurate model
- Measure data formats
- Select two potential data formats
- Markdown-like
- Structured Plaintext
- Generate a subset of data from flattened alerts
- Pass formats through ChatGPT to assess optimal format
- Select two potential data formats
- Measure potential Sentence Transformers
- Identify a set of potential Sentence Transformers
- Generate a subset of alerts (roughly 20-30) from the flattened alerts
- Create encodings of this subset of alerts with all potential sentence transformers
- Store these encodings in Milvus vector databases
- Connect these databases with the highest performing base LLM measured previously
- Query the LLM about a set of alerts and details from each vector database
- Output results to a set of plaintext files
- Review the results and establish a score for each transformer
- Encode full dataset with top two sentence transformers for final user testing
Base LLMs
Potential Base LLMs
- deepseek-r1: https://ollama.com/library/deepseek-r1
- deepseek-r1:8b
- "The model has demonstrated outstanding performance across various benchmark evaluations, including mathematics, programming, and general logic."
- This model was prone to freak-outs and paranoid ramblings, and was kind of racist
- gemma3: https://ollama.com/library/gemma3
- gemma3:12b
- "They excel in tasks like question answering, summarization, and reasoning, while their compact design allows deployment on resource-limited devices."
- qwen3: https://ollama.com/library/qwen3
- qwen3:8b
- "Achieves competitive results in benchmark evaluations of coding, math, general capabilities"
- llama4: https://ollama.com/library/llama4
- llama4:16x17b
- "Meta's latest collection of multimodal models."
- MUCH larger than other models
- This model wouldn't run on my device
- llama3.3: https://ollama.com/library/llama3.3
- llama3.3:70b
- Also quite large
- This model wouldn't run on my device
- llama3.2: https://ollama.com/library/llama3.2
- llama3.2:3b
- llama3.1: https://ollama.com/library/llama3.1
- llama3.1:8b
Testing Approach
For this test, we're attempting to determine which local LLM model can handle analyzing and answering questions about security alerts. We're not testing how well it can make these determinations from any internal data, only how well it can answer questions using its own training data.
We began by selecting ~10 internal alerts across different alert types. For each of the chosen alerts, we crafted ~5-10 questions for each alert. These questions were crafted to minimize ambiguity in responses. Example questions are:
- When did this alert arrive?
- Which account is suspected of fraud?
- What is the IP address of the device in question?
- What is the ServiceNow ticket number for this alert?
A script was then written and executed that queried each model with each question, and the results were written in CSV format. Once these results were generated, each answer was manually given a score using the following approach:
- 1.0: The answer was correct and complete
- 0.5: The answer was correct but incomplete
- 0.0: The answer was incorrect
Testing Results
After executing the testing script and scoring the responses, we calculated the base accuracy of each model using these scores.
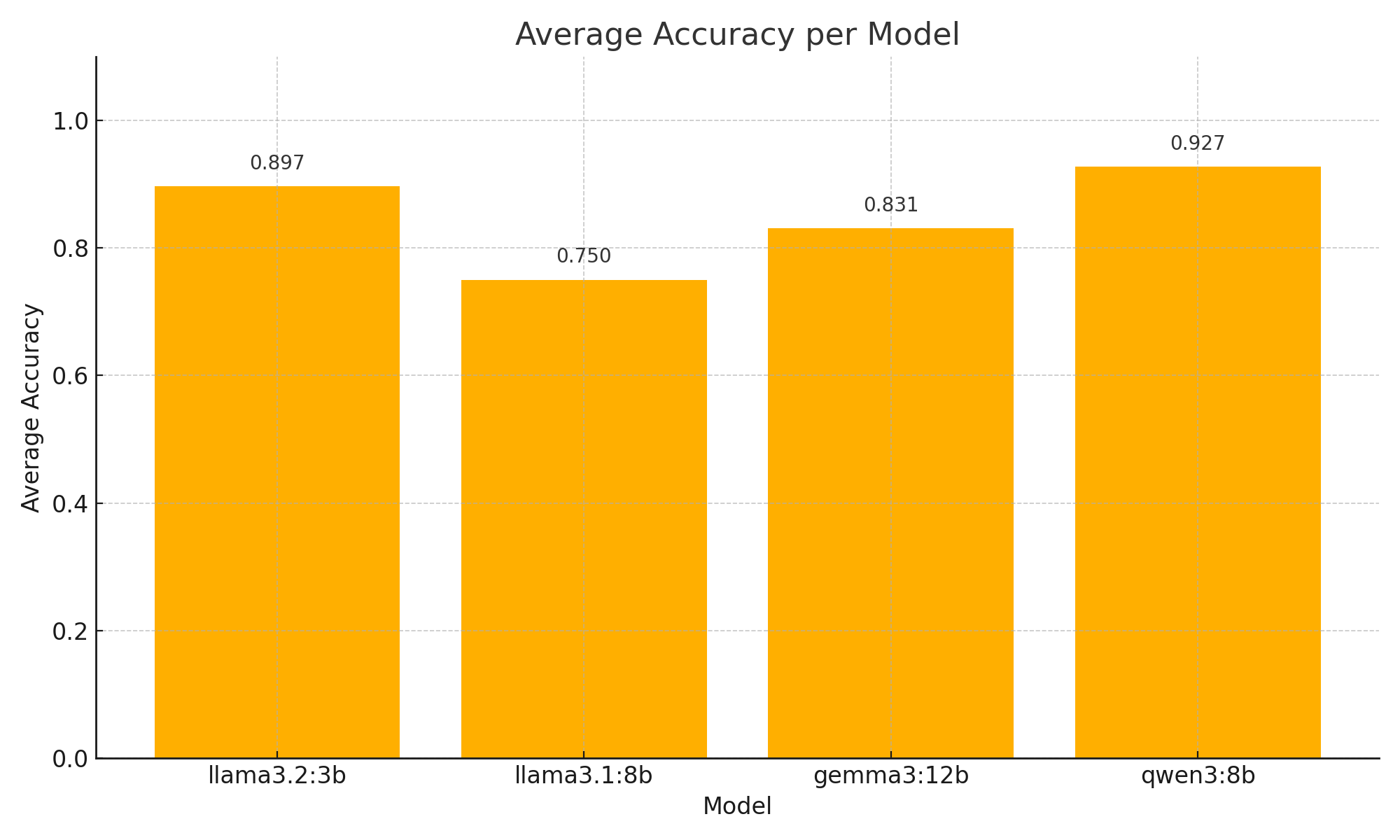
Most of the models' performances were similar, and none of the models were unable to reliably answer questions about the alerts. We can see that qwen3:8b is the most accurate, and llama3.2:3b is a close second.
However, examining the runtimes shows a striking difference between models.
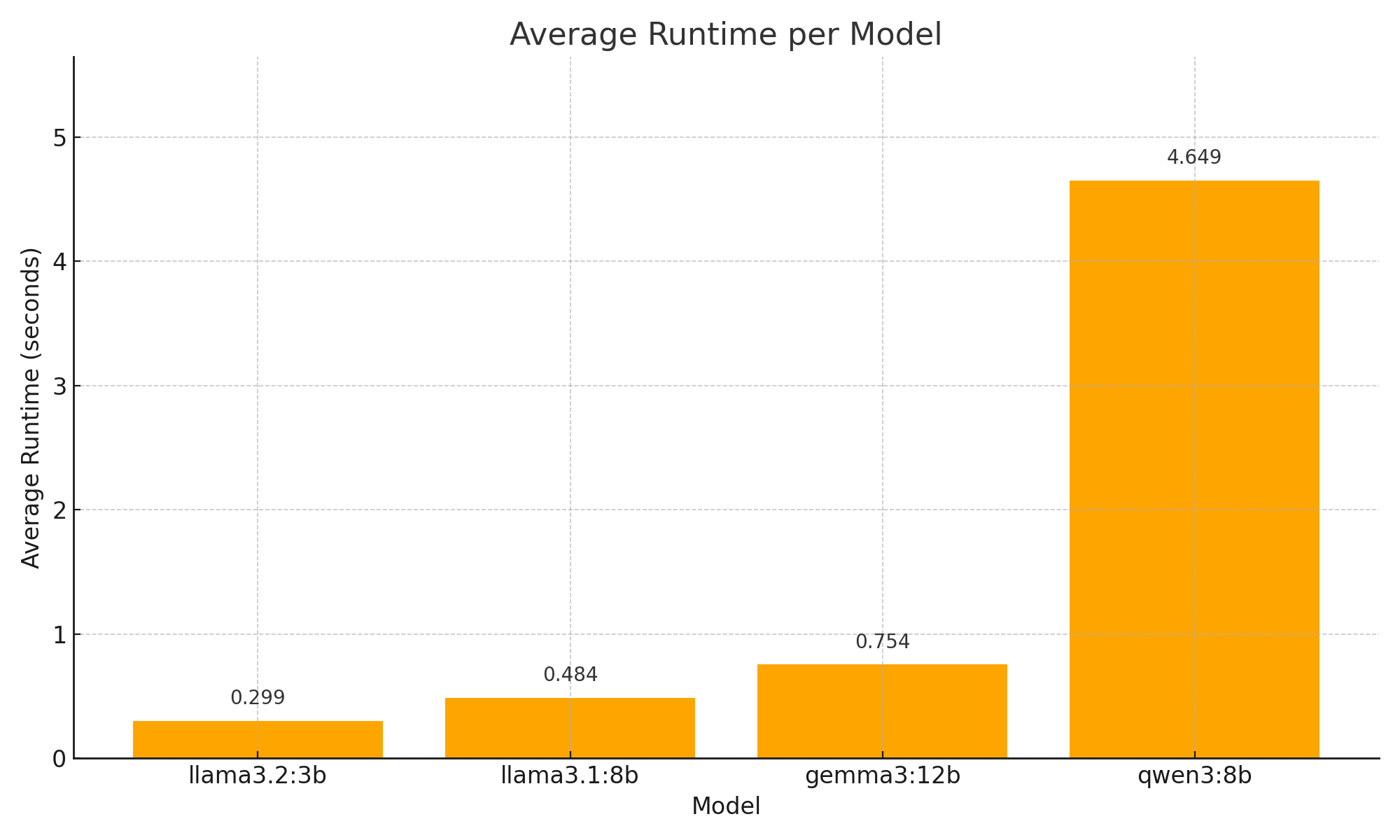
Even though qwen3:8b's performance is slightly better than llama3.2:3b, qwen3:8b's response time is over 10 times the speed of llama3.2:3b. Therefore, we'll be using llama3.2:3b for our subsequent agents, unless we find the answers are insufficient with more complex questions.
Sentence Transformers
- This project will be using SBERT Pretrained Models for Sentence Transformers, found here: https://www.sbert.net/docs/sentence_transformer/pretrained_models.html
Potential Models
- all-mpnet-base-v2: "All-round model tuned for many use-cases. Trained on a large and diverse dataset of over 1 billion training pairs."
- multi-qa-mpnet-base-dot-v1: "This model was tuned for semantic search: Given a query/question, it can find relevant passages. It was trained on a large and diverse set of (question, answer) pairs."
- all-distilroberta-v1: "All-round model tuned for many use-cases. Trained on a large and diverse dataset of over 1 billion training pairs."
- multi-qa-distilbert-cos-v1: "This model was tuned for semantic search: Given a query/question, it can find relevant passages. It was trained on a large and diverse set of (question, answer) pairs."
Testing Approach
For this test, we're attempting to determine both the best Sentence Transformer model and chunking strategy for our crawled and flattened data.
We first began by choosing a reasonable chunking strategy of 600-character chunks with 200-character overlap, create embeddings with each potential model, and store these embeddings in our vector database as unique collections.
We then constructed a set of questions that could be answered with this dataset and determined the chunk numbers that could be used to answer each question. This ground-truth set of questions and answer chunks was used to assess the efficacy of each model.
Once the embeddings were generated and stored in the vector database, and question / answer pairs were generated, we used a script to query each model with each question, and examine which chunks were returned from the vector database. We compared these results to our expected chunk values to calculate precision, recall, and F1.
Once the best Sentence Transformer model was identified, we repeated this process for different chunking strategies. For chunking, we selected four strategies to test:
- 400 character chunks with 100 character overlap
- 600 character chunks with 200 character overlap
- 800 character chunks with 200 character overlap
- 1000 character chunks with 250 character overlap
Since modifying the chunking strategy also changes the correct chunk numbers for each question, we updated our question / answer pairs for each of these chunking strategies. We then stored the embeddings for each chunking strategy in the vector database as unique collections, and used a script to query the database with each question, and calculate precision, recall, and F1 scores from these responses.
Results
The set of (question, valid chunk list) pairs was used to calculate recall@3, precision@3, and f1@3 to determine the most suitable model for our datasets.
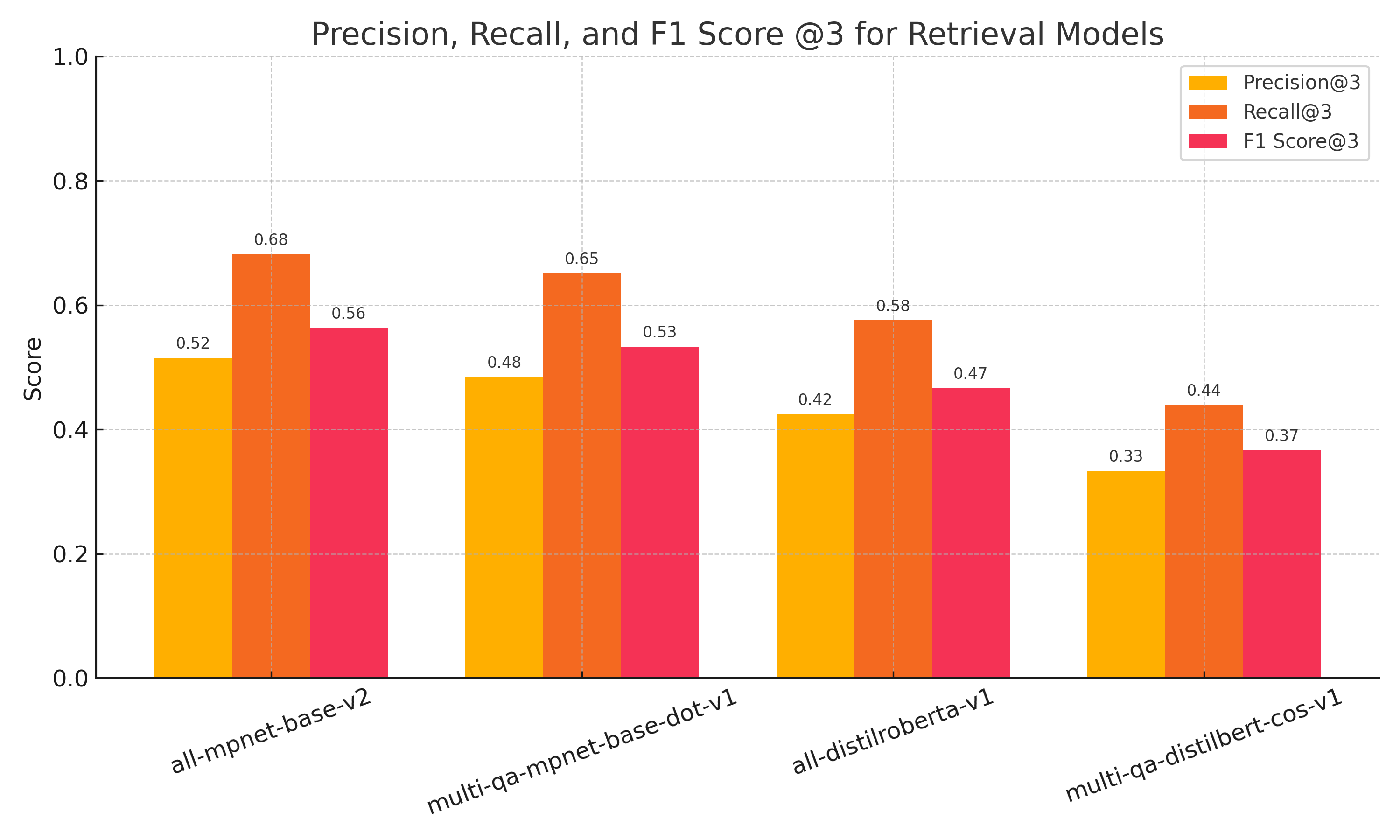
We can see from this graph that "all-mpnet-base-v2" has the best precision, recall, and f1 of the four models tested.
Next, we checked the response time of each model. We prefer a model that will return results in under one second, as to not make analysts wait longer than they could manually complete the research tasks.
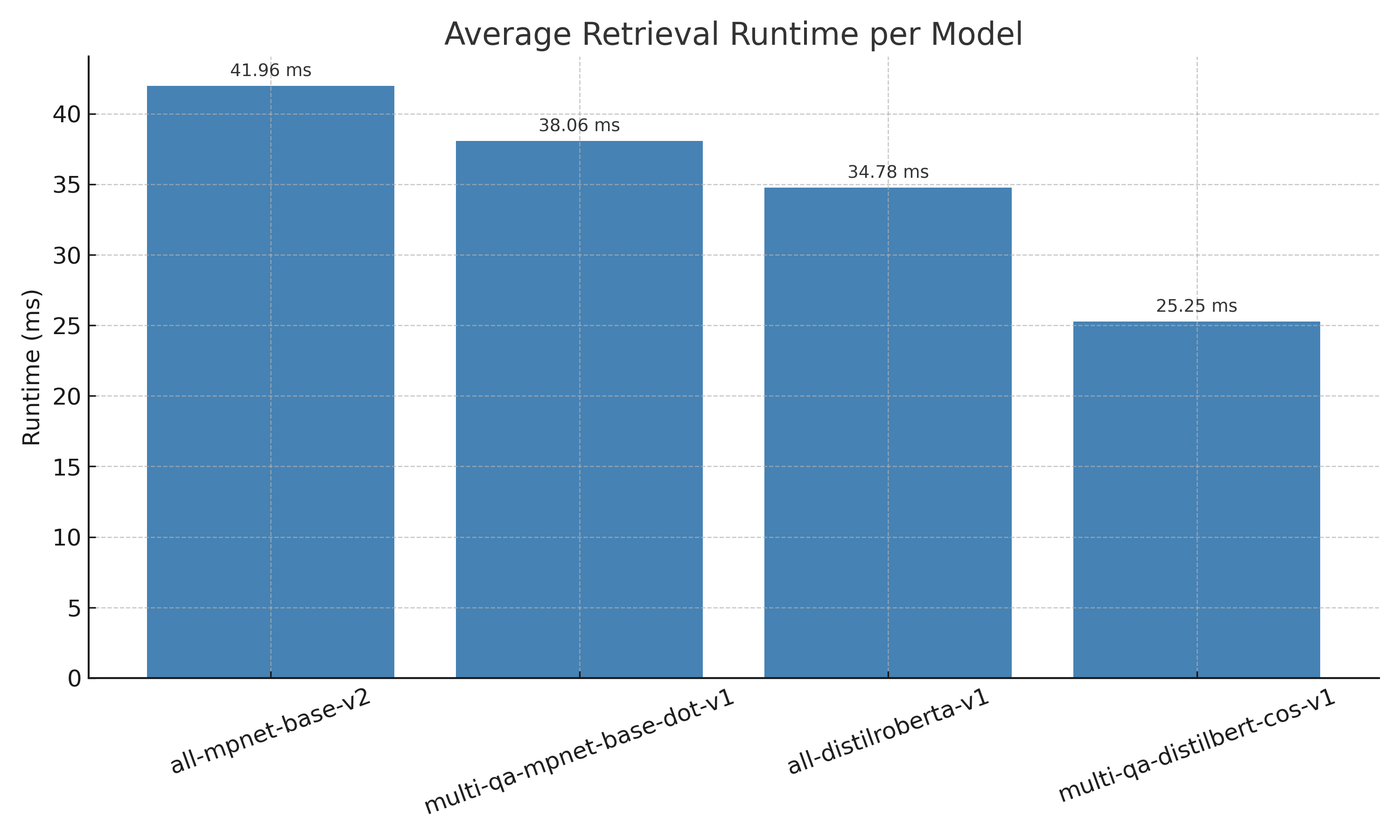
We did note that "all-mpnet-base-v2" was also the slowest of all models tested, but an average of ~42ms was well within our range of sufficient response time.
After selecting "all-mpnet-base-v2" as our Sentence Transformer model, we then examined several chunking methods for the data set and calculated precision, recall, and the F1 score for each model for several k. This was performed by using the same questions selected for evaluating each model, but with the valid chunks modified to reflect the new chunks.
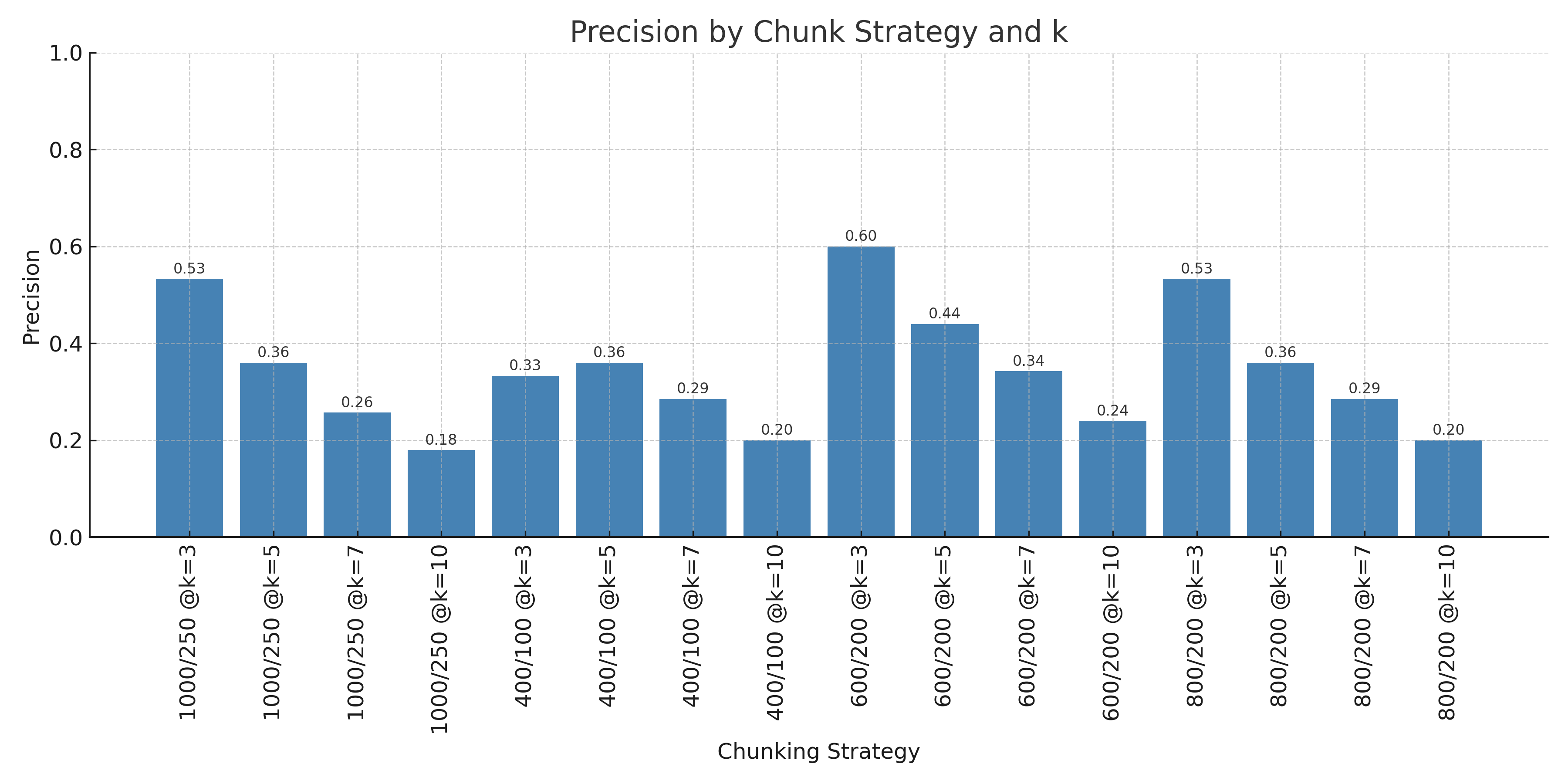
Looking at precision, we can see that a chunk size of 800 with an overlap of 200 likely has the best precision of each of the chunking strategies.
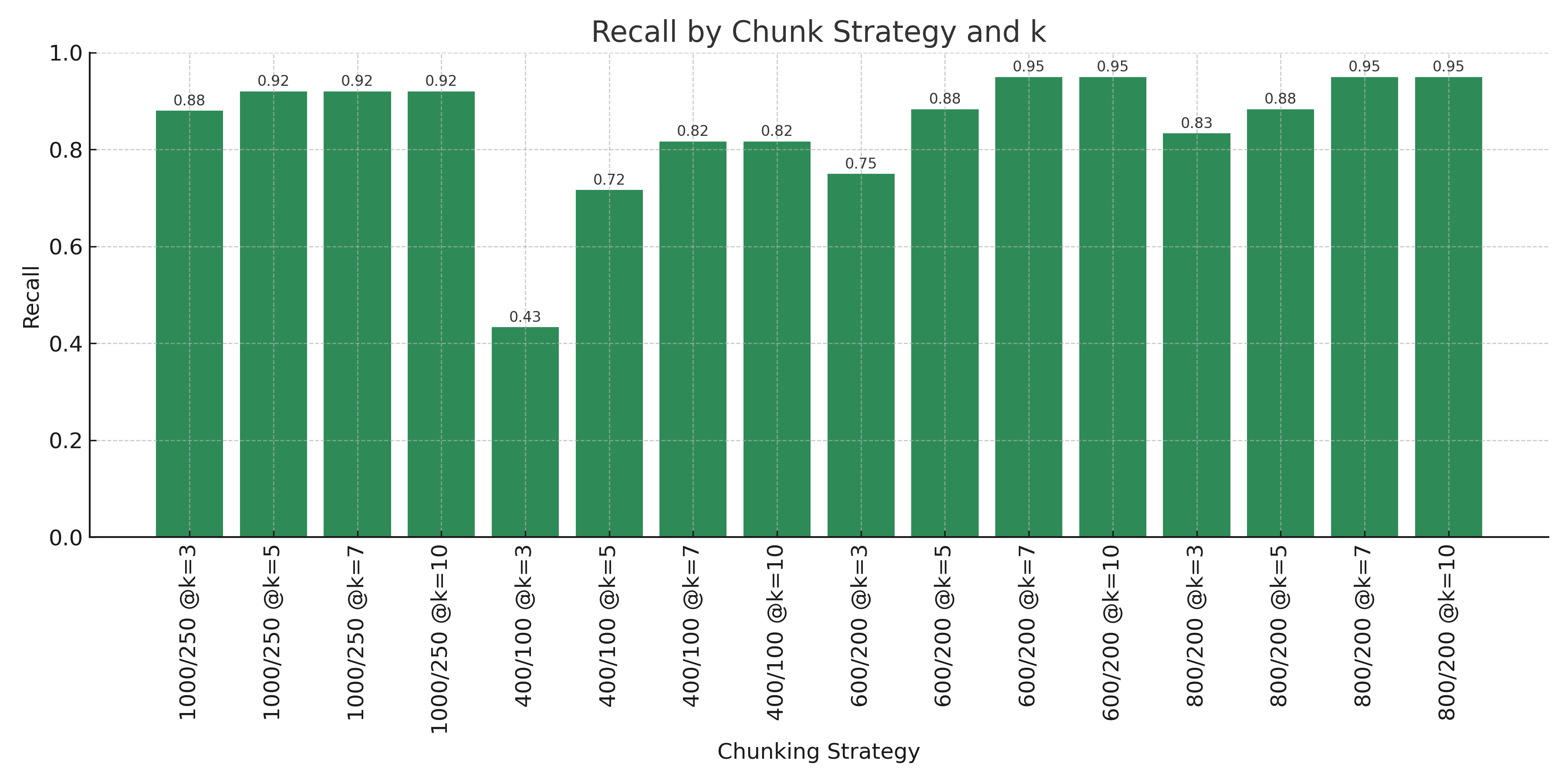
Similarly, a chunk size of 800 with an overlap of 200 has the best recall.
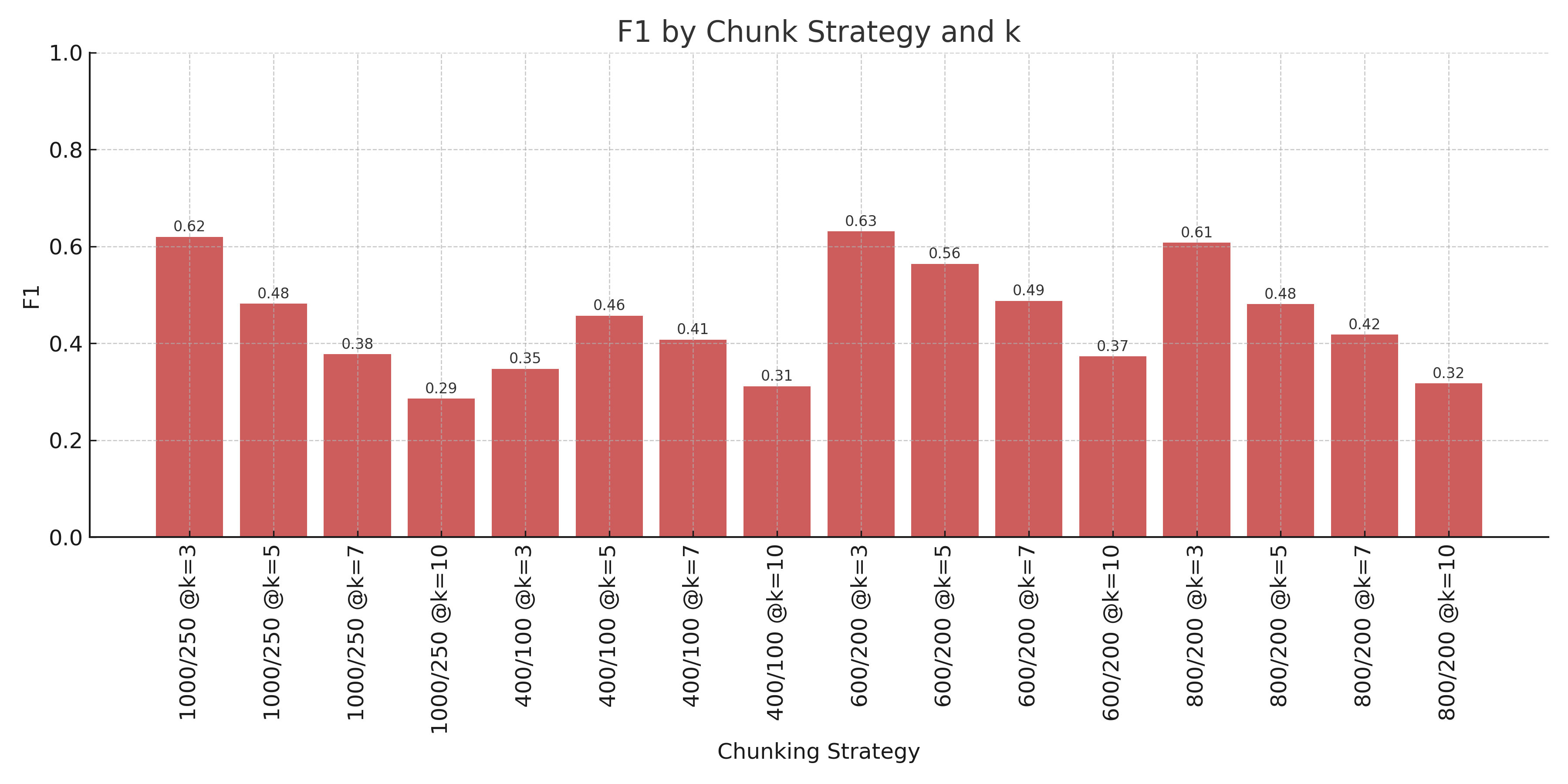
If we examine the F1 scores for each model, we can see that a chunk size of 800 with an overlap of 200 and a k value of 2 has the best F1 score. However, if we examine the precision@2 and recall@2 for this, we see precision@2 = 0.73, which is quite good, but recall@2 = 0.62, which is a bit lower than we'd like for this use case.
If we look at precision@3 and recall@3, we can see precision@3 = 0.55 and recall@3 = 0.68, which is closer to what we would like from our model performance. Therefore, we'll be using a chunking strategy of 800 character chunks with 200 character overlap with a k of 3.
Raw Results
Base LLM Scores
| test_number | model | runtime | accuracy |
|---|---|---|---|
| 1 | gemma3:12b | 0.370166 | 1 |
| 1 | gemma3:12b | 0.417108 | 1 |
| 1 | gemma3:12b | 0.468577 | 1 |
| 1 | gemma3:12b | 0.664739 | 0 |
| 1 | gemma3:12b | 0.763154 | 1 |
| 1 | gemma3:12b | 0.820844 | 1 |
| 1 | gemma3:12b | 0.872679 | 1 |
| 2 | gemma3:12b | 0.366531 | 1 |
| 2 | gemma3:12b | 0.47569 | 1 |
| 2 | gemma3:12b | 0.491826 | 1 |
| 2 | gemma3:12b | 0.517355 | 1 |
| 2 | gemma3:12b | 0.74842 | 0 |
| 2 | gemma3:12b | 0.848468 | 1 |
| 3 | gemma3:12b | 0.415405 | 1 |
| 3 | gemma3:12b | 0.611226 | 1 |
| 3 | gemma3:12b | 0.80082 | 1 |
| 3 | gemma3:12b | 0.929659 | 1 |
| 3 | gemma3:12b | 1.12996 | 1 |
| 3 | gemma3:12b | 4.98996 | 1 |
| 4 | gemma3:12b | 0.373089 | 1 |
| 4 | gemma3:12b | 0.503498 | 1 |
| 4 | gemma3:12b | 0.521959 | 1 |
| 4 | gemma3:12b | 0.67758 | 0 |
| 4 | gemma3:12b | 0.683183 | 1 |
| 4 | gemma3:12b | 0.856181 | 0 |
| 4 | gemma3:12b | 1.03495 | 1 |
| 5 | gemma3:12b | 0.40605 | 1 |
| 5 | gemma3:12b | 0.424437 | 1 |
| 5 | gemma3:12b | 0.615896 | 1 |
| 5 | gemma3:12b | 0.623662 | 1 |
| 5 | gemma3:12b | 0.811979 | 0.5 |
| 5 | gemma3:12b | 0.841387 | 1 |
| 5 | gemma3:12b | 1.10083 | 1 |
| 5 | gemma3:12b | 1.36328 | 1 |
| 6 | gemma3:12b | 0.312678 | 0.5 |
| 6 | gemma3:12b | 0.386787 | 1 |
| 6 | gemma3:12b | 0.50494 | 1 |
| 6 | gemma3:12b | 0.657137 | 1 |
| 6 | gemma3:12b | 0.667987 | 1 |
| 6 | gemma3:12b | 0.913233 | 1 |
| 6 | gemma3:12b | 1.36489 | 1 |
| 7 | gemma3:12b | 0.394641 | 1 |
| 7 | gemma3:12b | 0.452594 | 1 |
| 7 | gemma3:12b | 0.468084 | 1 |
| 7 | gemma3:12b | 0.544347 | 0.5 |
| 7 | gemma3:12b | 0.936324 | 1 |
| 7 | gemma3:12b | 1.85401 | 0 |
| 8 | gemma3:12b | 0.382302 | 0 |
| 8 | gemma3:12b | 0.390237 | 1 |
| 8 | gemma3:12b | 0.397763 | 1 |
| 8 | gemma3:12b | 0.549778 | 1 |
| 8 | gemma3:12b | 0.627466 | 1 |
| 8 | gemma3:12b | 0.88382 | 1 |
| 8 | gemma3:12b | 1.06052 | 0.5 |
| 9 | gemma3:12b | 0.398704 | 1 |
| 9 | gemma3:12b | 0.466214 | 1 |
| 9 | gemma3:12b | 0.638502 | 1 |
| 9 | gemma3:12b | 0.726306 | 0 |
| 9 | gemma3:12b | 0.83015 | 1 |
| 9 | gemma3:12b | 0.932743 | 1 |
| 9 | gemma3:12b | 1.45274 | 0.5 |
| 1 | llama3.1:8b | 0.278651 | 1 |
| 1 | llama3.1:8b | 0.307555 | 1 |
| 1 | llama3.1:8b | 0.343301 | 1 |
| 1 | llama3.1:8b | 0.41273 | 1 |
| 1 | llama3.1:8b | 0.516353 | 1 |
| 1 | llama3.1:8b | 0.626651 | 0 |
| 1 | llama3.1:8b | 0.672331 | 1 |
| 2 | llama3.1:8b | 0.259403 | 1 |
| 2 | llama3.1:8b | 0.433798 | 1 |
| 2 | llama3.1:8b | 0.491795 | 0 |
| 2 | llama3.1:8b | 0.546173 | 0 |
| 2 | llama3.1:8b | 0.641082 | 1 |
| 2 | llama3.1:8b | 0.698893 | 0.5 |
| 3 | llama3.1:8b | 0.189142 | 1 |
| 3 | llama3.1:8b | 0.293098 | 1 |
| 3 | llama3.1:8b | 0.370015 | 1 |
| 3 | llama3.1:8b | 0.443019 | 1 |
| 3 | llama3.1:8b | 0.621476 | 1 |
| 3 | llama3.1:8b | 2.18867 | 1 |
| 4 | llama3.1:8b | 0.129677 | 1 |
| 4 | llama3.1:8b | 0.180741 | 1 |
| 4 | llama3.1:8b | 0.226597 | 0 |
| 4 | llama3.1:8b | 0.240928 | 1 |
| 4 | llama3.1:8b | 0.273571 | 1 |
| 4 | llama3.1:8b | 0.2808 | 1 |
| 4 | llama3.1:8b | 0.287894 | 1 |
| 5 | llama3.1:8b | 0.116565 | 1 |
| 5 | llama3.1:8b | 0.148462 | 1 |
| 5 | llama3.1:8b | 0.164589 | 0 |
| 5 | llama3.1:8b | 0.200734 | 1 |
| 5 | llama3.1:8b | 0.363565 | 1 |
| 5 | llama3.1:8b | 0.450078 | 1 |
| 5 | llama3.1:8b | 0.451592 | 1 |
| 5 | llama3.1:8b | 0.742867 | 0.5 |
| 6 | llama3.1:8b | 0.148577 | 0.5 |
| 6 | llama3.1:8b | 0.242421 | 1 |
| 6 | llama3.1:8b | 0.315101 | 0 |
| 6 | llama3.1:8b | 0.340314 | 1 |
| 6 | llama3.1:8b | 0.374 | 1 |
| 6 | llama3.1:8b | 0.403524 | 1 |
| 6 | llama3.1:8b | 0.716228 | 1 |
| 7 | llama3.1:8b | 0.356602 | 1 |
| 7 | llama3.1:8b | 0.471415 | 1 |
| 7 | llama3.1:8b | 1.07084 | 0 |
| 7 | llama3.1:8b | 1.09345 | 0 |
| 7 | llama3.1:8b | 1.16909 | 1 |
| 7 | llama3.1:8b | 1.78262 | 0.5 |
| 8 | llama3.1:8b | 0.294912 | 1 |
| 8 | llama3.1:8b | 0.355763 | 0 |
| 8 | llama3.1:8b | 0.365827 | 1 |
| 8 | llama3.1:8b | 0.40703 | 1 |
| 8 | llama3.1:8b | 0.591506 | 1 |
| 8 | llama3.1:8b | 0.657684 | 0 |
| 8 | llama3.1:8b | 1.10461 | 0 |
| 9 | llama3.1:8b | 0.248994 | 1 |
| 9 | llama3.1:8b | 0.256581 | 1 |
| 9 | llama3.1:8b | 0.356843 | 1 |
| 9 | llama3.1:8b | 0.384837 | 1 |
| 9 | llama3.1:8b | 0.428954 | 1 |
| 9 | llama3.1:8b | 0.460256 | 0 |
| 9 | llama3.1:8b | 1.03929 | 0.5 |
| 1 | llama3.2:3b | 0.123196 | 1 |
| 1 | llama3.2:3b | 0.199323 | 1 |
| 1 | llama3.2:3b | 0.231757 | 1 |
| 1 | llama3.2:3b | 0.242375 | 1 |
| 1 | llama3.2:3b | 0.292086 | 1 |
| 1 | llama3.2:3b | 0.503381 | 0.5 |
| 1 | llama3.2:3b | 0.673257 | 0 |
| 2 | llama3.2:3b | 0.159802 | 1 |
| 2 | llama3.2:3b | 0.226598 | 1 |
| 2 | llama3.2:3b | 0.264125 | 1 |
| 2 | llama3.2:3b | 0.309718 | 0.5 |
| 2 | llama3.2:3b | 0.490389 | 1 |
| 2 | llama3.2:3b | 0.507146 | 1 |
| 3 | llama3.2:3b | 0.154477 | 1 |
| 3 | llama3.2:3b | 0.19552 | 1 |
| 3 | llama3.2:3b | 0.24607 | 1 |
| 3 | llama3.2:3b | 0.269585 | 1 |
| 3 | llama3.2:3b | 0.388775 | 1 |
| 3 | llama3.2:3b | 1.50039 | 1 |
| 4 | llama3.2:3b | 0.150194 | 1 |
| 4 | llama3.2:3b | 0.179274 | 1 |
| 4 | llama3.2:3b | 0.196236 | 1 |
| 4 | llama3.2:3b | 0.203428 | 1 |
| 4 | llama3.2:3b | 0.252301 | 1 |
| 4 | llama3.2:3b | 0.289747 | 1 |
| 4 | llama3.2:3b | 0.782877 | 1 |
| 5 | llama3.2:3b | 0.131955 | 1 |
| 5 | llama3.2:3b | 0.140762 | 1 |
| 5 | llama3.2:3b | 0.237611 | 1 |
| 5 | llama3.2:3b | 0.246194 | 1 |
| 5 | llama3.2:3b | 0.299858 | 0 |
| 5 | llama3.2:3b | 0.305543 | 1 |
| 5 | llama3.2:3b | 0.377538 | 1 |
| 5 | llama3.2:3b | 0.390736 | 1 |
| 6 | llama3.2:3b | 0.167363 | 1 |
| 6 | llama3.2:3b | 0.167575 | 1 |
| 6 | llama3.2:3b | 0.215173 | 1 |
| 6 | llama3.2:3b | 0.217776 | 0.5 |
| 6 | llama3.2:3b | 0.263251 | 1 |
| 6 | llama3.2:3b | 0.293397 | 1 |
| 6 | llama3.2:3b | 0.330149 | 1 |
| 7 | llama3.2:3b | 0.167087 | 1 |
| 7 | llama3.2:3b | 0.177397 | 1 |
| 7 | llama3.2:3b | 0.194063 | 1 |
| 7 | llama3.2:3b | 0.261761 | 0.5 |
| 7 | llama3.2:3b | 0.326456 | 1 |
| 7 | llama3.2:3b | 0.639461 | 0 |
| 8 | llama3.2:3b | 0.130855 | 1 |
| 8 | llama3.2:3b | 0.156924 | 1.1 |
| 8 | llama3.2:3b | 0.23556 | 1 |
| 8 | llama3.2:3b | 0.240756 | 1 |
| 8 | llama3.2:3b | 0.251869 | 1 |
| 8 | llama3.2:3b | 0.252823 | 1 |
| 8 | llama3.2:3b | 0.283703 | 1 |
| 9 | llama3.2:3b | 0.137193 | 1 |
| 9 | llama3.2:3b | 0.179997 | 1 |
| 9 | llama3.2:3b | 0.2257 | 1 |
| 9 | llama3.2:3b | 0.264985 | 1 |
| 9 | llama3.2:3b | 0.41487 | 1 |
| 9 | llama3.2:3b | 0.530856 | 1 |
| 9 | llama3.2:3b | 0.649395 | 0.5 |
| 1 | qwen3:8b | 2.70072 | 1 |
| 1 | qwen3:8b | 2.87567 | 1 |
| 1 | qwen3:8b | 2.91428 | 1 |
| 1 | qwen3:8b | 3.02228 | 1 |
| 1 | qwen3:8b | 3.46477 | 1 |
| 1 | qwen3:8b | 4.28136 | 1 |
| 1 | qwen3:8b | 4.62121 | 1 |
| 2 | qwen3:8b | 1.96874 | 1 |
| 2 | qwen3:8b | 3.52389 | 1 |
| 2 | qwen3:8b | 4.1465 | 1 |
| 2 | qwen3:8b | 4.70524 | 1 |
| 2 | qwen3:8b | 5.25586 | 1 |
| 2 | qwen3:8b | 6.74846 | 0.5 |
| 3 | qwen3:8b | 3.59101 | 1 |
| 3 | qwen3:8b | 3.65445 | 1 |
| 3 | qwen3:8b | 4.01018 | 1 |
| 3 | qwen3:8b | 4.36624 | 1 |
| 3 | qwen3:8b | 4.61195 | 1 |
| 3 | qwen3:8b | 11.2382 | 1 |
| 4 | qwen3:8b | 2.4661 | 1 |
| 4 | qwen3:8b | 3.76136 | 1 |
| 4 | qwen3:8b | 4.13932 | 1 |
| 4 | qwen3:8b | 5.71608 | 1 |
| 4 | qwen3:8b | 5.74301 | 1 |
| 4 | qwen3:8b | 8.35425 | 1 |
| 4 | qwen3:8b | 11.3324 | 0 |
| 5 | qwen3:8b | 2.35912 | 1 |
| 5 | qwen3:8b | 2.45854 | 1 |
| 5 | qwen3:8b | 2.60316 | 1 |
| 5 | qwen3:8b | 2.77813 | 1 |
| 5 | qwen3:8b | 2.80748 | 1 |
| 5 | qwen3:8b | 3.79972 | 1 |
| 5 | qwen3:8b | 3.88815 | 1 |
| 5 | qwen3:8b | 4.9955 | 1 |
| 6 | qwen3:8b | 2.32712 | 1 |
| 6 | qwen3:8b | 3.54135 | 1 |
| 6 | qwen3:8b | 3.63473 | 1 |
| 6 | qwen3:8b | 4.37926 | 1 |
| 6 | qwen3:8b | 4.54156 | 1 |
| 6 | qwen3:8b | 5.6432 | 1 |
| 6 | qwen3:8b | 5.7177 | 1 |
| 7 | qwen3:8b | 3.1017 | 1 |
| 7 | qwen3:8b | 5.47979 | 1 |
| 7 | qwen3:8b | 6.18008 | 1 |
| 7 | qwen3:8b | 10.6943 | 1 |
| 7 | qwen3:8b | 13.9764 | 0 |
| 7 | qwen3:8b | 16.4295 | 0.5 |
| 8 | qwen3:8b | 2.21505 | 1 |
| 8 | qwen3:8b | 2.69782 | 1 |
| 8 | qwen3:8b | 2.70046 | 1 |
| 8 | qwen3:8b | 2.80097 | 1 |
| 8 | qwen3:8b | 3.18436 | 1 |
| 8 | qwen3:8b | 3.48221 | 1 |
| 8 | qwen3:8b | 4.64511 | 1 |
| 9 | qwen3:8b | 3.17326 | 1 |
| 9 | qwen3:8b | 3.5276 | 1 |
| 9 | qwen3:8b | 4.72399 | 1 |
| 9 | qwen3:8b | 4.76546 | 1 |
| 9 | qwen3:8b | 4.88178 | 1 |
| 9 | qwen3:8b | 4.98362 | 1 |
| 9 | qwen3:8b | 5.93178 | 0.5 |
Embedding Model Scores
| model | runtime | precision@3 | recall@3 | F1 score@3 |
|---|---|---|---|---|
| all-mpnet-base-v2 | 0.04196 | 0.51515 | 0.68182 | 0.56364 |
| multi-qa-mpnet-base-dot-v1 | 0.03806 | 0.48485 | 0.65152 | 0.53333 |
| all-distilroberta-v1 | 0.03478 | 0.42424 | 0.57576 | 0.46667 |
| multi-qa-distilbert-cos-v1 | 0.02525 | 0.33333 | 0.43939 | 0.36667 |
Chunk Size Scores
| chunk size / overlap | k | precision | recall | f1 | Average runtime |
|---|---|---|---|---|---|
| 1000/250 | 3 | 0.533333 | 0.88 | 0.62 | 0.0534844 |
| 1000/250 | 5 | 0.36 | 0.92 | 0.481905 | 0.0158076 |
| 1000/250 | 7 | 0.257143 | 0.92 | 0.377778 | 0.0158098 |
| 1000/250 | 10 | 0.18 | 0.92 | 0.286061 | 0.0168777 |
| 400/100 | 3 | 0.333333 | 0.433333 | 0.347619 | 0.0533583 |
| 400/100 | 5 | 0.36 | 0.716667 | 0.457143 | 0.0162182 |
| 400/100 | 7 | 0.285714 | 0.816667 | 0.407980 | 0.0156493 |
| 400/100 | 10 | 0.2 | 0.816667 | 0.311822 | 0.0161057 |
| 600/200 | 3 | 0.6 | 0.75 | 0.631429 | 0.0537768 |
| 600/200 | 5 | 0.44 | 0.883333 | 0.564286 | 0.0160496 |
| 600/200 | 7 | 0.342857 | 0.95 | 0.487980 | 0.0155894 |
| 600/200 | 10 | 0.24 | 0.95 | 0.373360 | 0.0178685 |
| 800/200 | 3 | 0.533333 | 0.833333 | 0.607619 | 0.0533951 |
| 800/200 | 5 | 0.36 | 0.883333 | 0.480952 | 0.0163289 |
| 800/200 | 7 | 0.285714 | 0.95 | 0.417980 | 0.0157671 |
| 800/200 | 10 | 0.2 | 0.95 | 0.317416 | 0.0162362 |